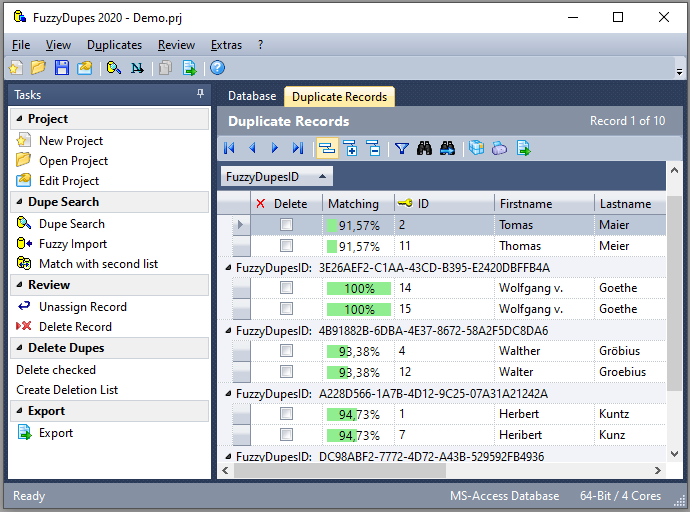
Projekt Assistent
Wählen Sie im Hauptmenü
"Datei->Neues Projekt".
Es öffnet sich der Projekt Assistent.
Datenverbindung
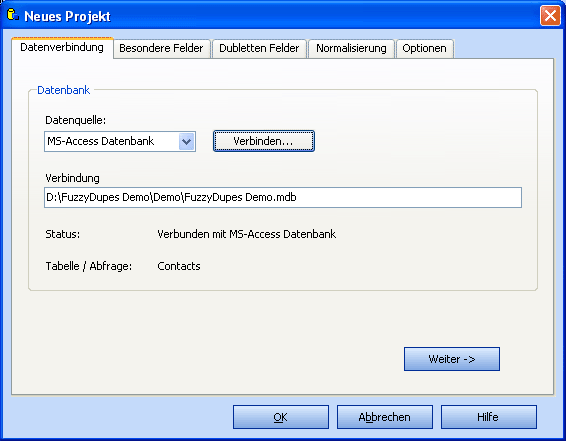
Wählen Sie eine der folgenden Datenquellen:
- MS-Access Datenbank
- MS SQL-Server Datenbank
- MS-Excel Tabelle
- Textdatei mit Delimiter (CSV Dateien)
- MS-Outlook Kontakt Ordner
- Windows Adressbuch
- SharePoint Server
- BulkMailer Addresses Database
- Andere (Datenlink Dialog)
Klicken Sie auf auf Verbinden. Abhängig von der gewählten Datenquelle folgen weitere Optionen.
Sie können sich grundsätzlich mit allen Datenbanken verbinden, die über einen ODBC-Treiber
oder einen OLE-DB-Provider verfügen, z.B. auch Oracle und MySQL.
- Laden Sie einen entsprechenden ODBC-Treiber von der Website des Datenbankherstellers.
- Erstellen Sie ggf. über den ODBC-Manager (Systemsteuerung) eine Systemdatenquelle.
- Wählen Sie hier "Andere (Datenlink Dialog)"
- Stellen Sie eine Verbindung zu Ihrer Datenbank her
- Im Datenverknüpfungseigenschaften Dialog markieren Sie u.U. Kennwort speichern, damit ein späterer Zugriff erfolgen kann.
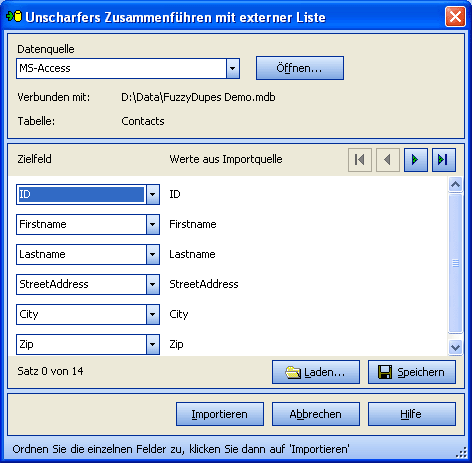
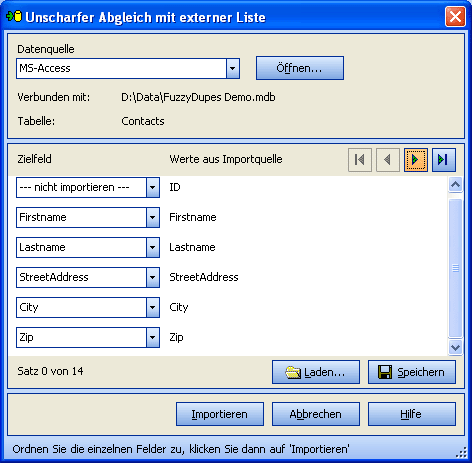
Wählen Sie anschließend die Tabelle, welche Ihre Daten enthält.
Klicken Sie dann auf "Weiter".
Besondere Felder
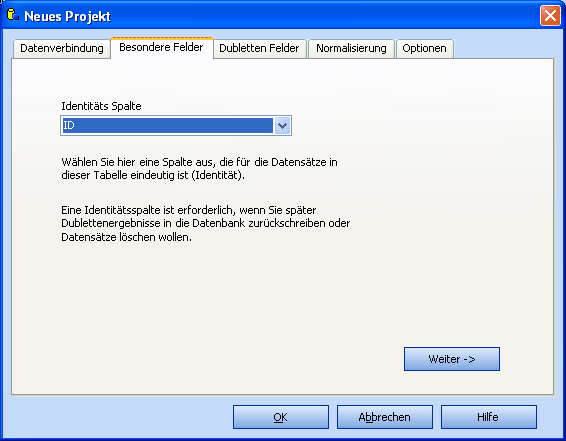
Wählen Sie eine Spalte aus Ihrer Tabelle, welche eindeutige Werte besitzt
(Identitätsspalte). Diese Spalte sollte auch einen Primärschlüssel besitzen.
Dubletten Felder
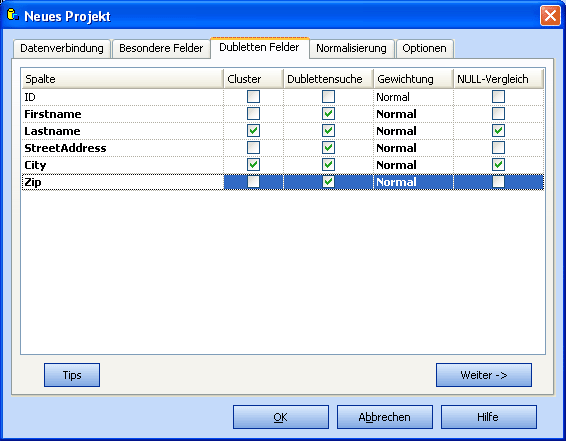
Markieren Sie 2-4 (in Einzelfällen auch mehr) Spalten, die für die Clusterbildung herangezogen werden sollen.
Diese Spalten sollten sehr gut mit Daten gefüllt sein.
Wählen Sie hier nur Spalten vom Typ Zeichenkette. Postleitzahlen sind für die Clusterbildung ungeeignet.
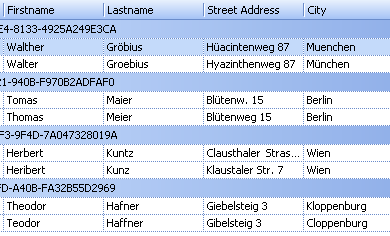
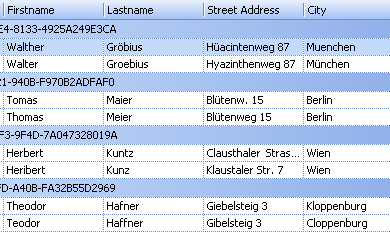
Bei Adressdaten wählen Sie z.B. Nachname, Straße, Ort
Markieren Sie mehrere Felder, die für die Dublettensuche herangezogen werden sollen.
Markieren Sie möglichst mehr als 3 Felder.
Bei Adressdaten wählen Sie typischerweise
- Nachname
- Vorname
- (Firma)
- PLZ
- Strasse
- Ort
- [Telefon]
- [..]
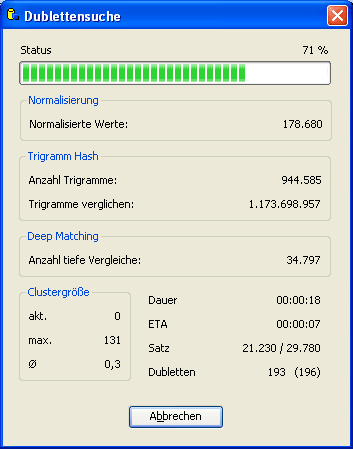
Innerhalb der markierten Felder wird das Programm dann bei der Dublettensuche mit Hilfe von
unscharfen Vergleichsalgorithmen jeweils eine Übereinstimmung berechnen. Anschliessend wird daraus die
durchschnittliche Übereinstimmung zweier Datensätze berechnet.
Belassen Sie im Normalfall alle Gewichtungen auf Normal.
Falls gewünscht, können Sie einzelne Spalten mehr oder weniger stark gewichten.
Wählen Sie Identisch, wenn beim Vergleich in dieser Spalte exakte Übereinstimmung erforderlich ist.
Die Option "Identisch" ist insbesondere bei gruppierten Daten sinnvoll, wobei Dubletten nur innerhalb
definierter Gruppen auftreten dürfen. Wählen Sie dabei für die Gruppenspalte Identisch.
Identität funktioniert auch in Verbindung mit numerischen Werten, z.B. einer Firmen-ID.
Markieren Sie NULL-Vergleich für Spalten, die in den allermeisten Sätzen Werte enthalten
(z.B. Nachname, Straße, PLZ, Ort). Für sonstige Spalten, die in Ihrer Datenbank schlecht gefüllt sind,
markieren Sie NULL-Vergleich nicht (z.B. Vorname, Telefon, Fax, ...).
Beim NULL-Vergleich werden auch leere Einträge (NULL-Werte) für die Berechnung der
durchschnittlichen Übereinstimmung herangezogen.
Klicken Sie dann auf "Weiter".
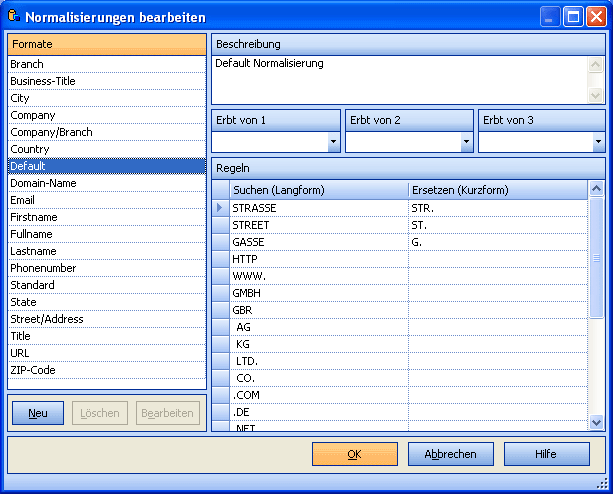
Normalisierung
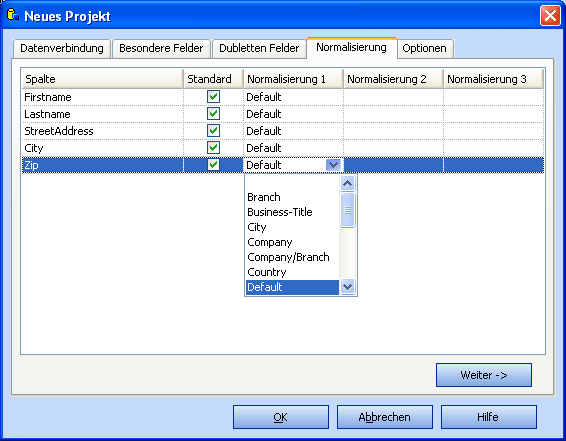
Standard Normalisierung wandelt die Zeichen in Großbuchstaben um,
ersetzt Sonderzeichen und Umlaute, dopplelte Leerzeichen, etc.
Wählen Sie bis zu 3 verschiedene Normalisierungs-Regeln pro Datenbank-Spalte.
Wählen Sie "default" bei Adressdaten, wenn Sie unsicher sind oder wenn Sie
keine benutzerdefinierten Normalisierungsregeln angelegt haben.
Verwenden Sie den Normalisierungs Editor um Regeln zu bearbeiten oder neue Regeln zu erstellen.
Optionen
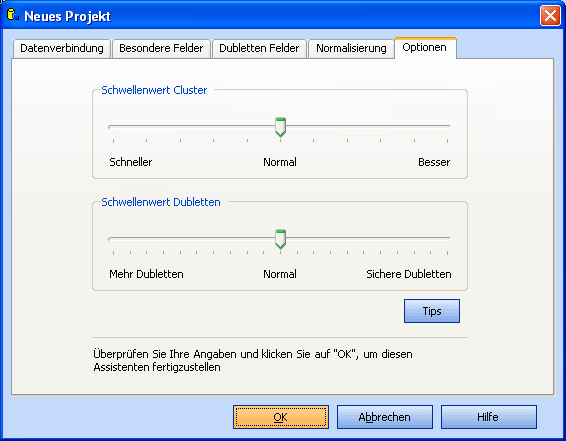
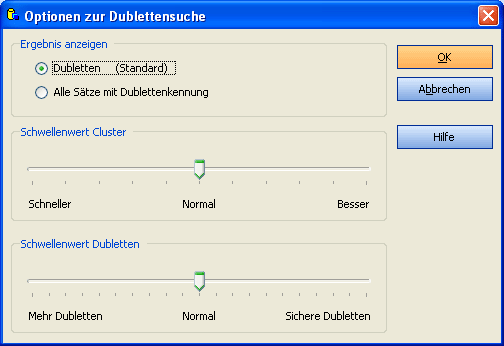
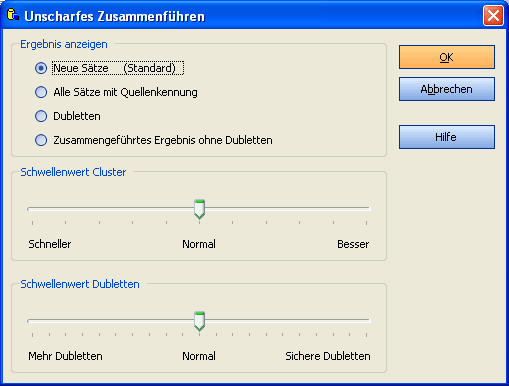
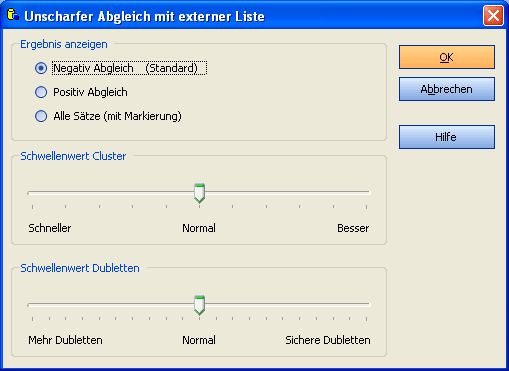
Hiermit können Sie Einfluss auf die Clustergröße nehmen.
In den meisten Fällen belassen Sie diesen Regler in der mittleren Position.
Es bringt nichts, wenn Sie den Regler ganz nach rechts schieben, der Suchvorgang wird nur wesentlich verlangsamt.
Schieben Sie den Regler bei großen Datenbanken etwas nach links, um die Clustergröße zu verkleinern und die Suche dadurch zu beschleunigen.
Diese Einstellung hat großen Einfluß auf das Suchergebnis.
Wählen sie einen Schwellenwert für die Übereinstimmung.
Standard ist 90. Sie können später die Dublettensuche mit einem anderen
Schwellenwert wiederholen. Erhöhen Sie diesen Wert, wenn zuviele Dubletten gefunden wurden.
Wählen Sie einen niedrigeren Wert, wenn zuwenige Dubletten gefunden wurden.
Überprüfen Sie Ihre Angaben und klicken Sie auf "OK", um diesen Assistenten zu beenden.